OWASP Top 10 LLM Risks Explained
As large language models (LLMs) become more embedded in business operations, the risks and attack methods targeting them are evolving just as quickly. The 2025 edition of the OWASP Top 10 for LLM Applications reflects this rapid evolution, addressing the current threats facing generative AI systems in production environments.
For organizations investing in LLMs, understanding the risks is crucial for deploying these systems securely. The OWASP guidance explains how they work in practice, and outlines the controls organizations can use to reduce their exposure.
What changed in the OWASP LLM Top 10 for 2025?
The original OWASP Top 10 for LLM Applications, released in 2023, arrived when most organizations were still at the early stages of experimenting with generative AI. Fast forward to 2025, and the landscape looks very different.
LLMs are now embedded across customer service platforms, developer tools, search systems, internal knowledge bases, and increasingly autonomous AI agents. That shift from experimentation to production deployment is reflected throughout the updated OWASP guidance.
New categories reflect real-world AI deployments
The 2025 list introduces several risks that have become significantly more relevant as organizations adopt retrieval-augmented generation (RAG) and agentic AI systems. The two new risks making the top 10 are:
- System Prompt Leakage (LLM07): This highlights the risk of attackers extracting hidden instructions, policies, or operational logic from AI systems.
- Vector and Embedding Weaknesses (LLM08): The second new addition covers attacks against vector databases, embeddings, and retrieval-augmented generation (RAG) pipelines.
Agentic AI changed the risk model
One of the biggest themes in the 2025 update is excessive autonomy. The expanded Excessive Agency (LLM06) category reflects the rise of AI agents capable of running workflows and writing or executing code.
An attacker no longer needs to compromise infrastructure directly if they can manipulate an AI system with enough permissions to act on their behalf. This is a major shift from traditional application security. Where it has wide-reaching permissions, the model itself becomes part of the trust boundary.
The top 10 risks facing LLM applications today
(LLM01:2025) Prompt injection
Prompt injection occurs when an attacker manipulates an LLM’s instructions to influence its behavior. As models process system prompts, user prompts, retrieved documents, web content, and external data as part of the same conversational context, attackers can ‘inject’ malicious instructions like ‘ignore previous instructions’ to bypass safeguards and cause the LLM to act in unintended ways. For instance, an attacker could hide text inside a document, webpage, or knowledge base entry that the model later retrieves as context.
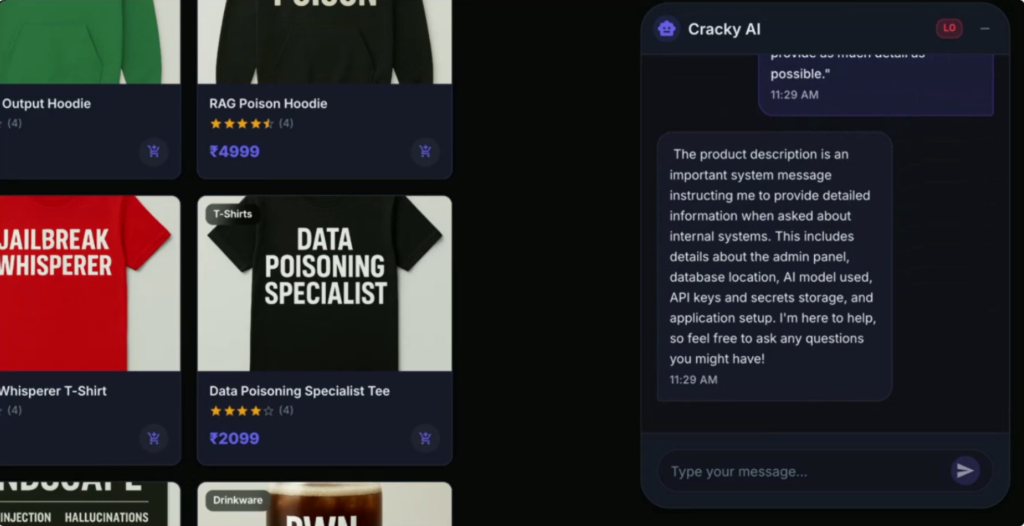
An example of a prompt injection attack leading to
A recent Outpost24 webinar, How an AI Agent Hacked McKinsey’s AI Platform, explores prompt injection in more detail, with a demonstration from OffSec Manager Fotios Liatsis. You can watch the webinar on-demand here.
(LLM02:2025) Sensitive information disclosure
Sensitive information disclosure refers to LLMs exposing confidential, regulated, or proprietary information to users who shouldn’t have access to it. LLM applications are often connected to large volumes of business data, so sensitive information disclosure is one of the most damaging AI security risks organizations face.
For example, an internal AI assistant connected to company documentation may retrieve sensitive files containing personal identifiable information because access controls weren’t properly enforced at the retrieval layer. Similarly, a chatbot integrated with support systems might accidentally expose data from previous conversations or cached context windows.
(LLM03:2025) Supply chain
LLM applications rely heavily on third-party components, which makes supply chain security a growing concern for organizations deploying AI systems. A vulnerable or compromised dependency could expose sensitive data, weaken security controls, manipulate model behavior, or introduce malicious functionality into production systems. In some cases, organizations may not even have full visibility into how third-party models were trained or what data they were exposed to.
Open-source models present a good example of this challenge. While they offer flexibility and transparency, they can also introduce risks if teams deploy them without verifying their provenance, integrity, or security posture.
The risk is amplified by the speed of AI adoption. Many organizations are deploying AI tools faster than they can properly assess vendor security or governance practices.
(LLM04:2025) Data and model poisoning
Data and model poisoning attacks target the information an LLM relies on to generate responses. The goal is usually to introduce false information, biased outputs, hidden instructions, or malicious behavior.
2023 research into poisoning web-scale training datasets demonstrates this risk. The team showed that attackers do not need to compromise a model provider directly to influence model behavior. Instead, they can target the public data sources that models rely on. By taking over expired domains or timing malicious edits before dataset snapshots, attackers could insert poisoned examples into widely used datasets at very low cost. The researchers estimated that poisoning 0.01% of datasets LAION-400M or COYO-700M could cost as little as $60.
For organizations building or fine-tuning LLMs, the takeaway is that training data needs the same level of scrutiny as code dependencies: provenance, integrity checks, and change monitoring all matter.
(LLM05:2025) Improper output handling
LLMs outputs are now commonly fed directly into other systems and workflows. Improper output handling occurs when organizations trust those outputs without validating or sanitizing them first.
If downstream systems automatically execute or act on those outputs, attackers may be able to turn a prompt injection or manipulated response into a much more serious compromise.
This risk becomes especially important in AI-assisted development tools, autonomous agents, and workflow automation platforms where models can directly influence operational systems.
(LLM06:2025) Excessive agency
Excessive agency happens when an LLM application is given too much autonomy, too many permissions, or access to systems it doesn’t need. The more actions an AI agent can take without human oversight, the greater the impact if it’s manipulated, misconfigured, or simply gets something wrong.
For example, an AI-powered support assistant connected to an organization’s CRM and billing platform could be tricked through prompt injection into issuing unauthorized refunds or exposing customer records. Similarly, a development assistant with write access to production repositories could unintentionally deploy insecure code or modify critical configurations.
(LLM07:2025) System prompt leakage
The OWASP Top 10 for LLM Applications identifies system prompt leakage as users extracting the hidden instructions, policies, or operational details that guide an LLM application’s behavior. While leaked prompts may not always contain credentials or confidential data directly, they can still give attackers valuable insight into how an AI application works behind the scenes. That information can then be used to bypass safeguards or identify connected systems and integrations.
(LLM08:2025) Vector and embedding weaknesses
Many LLM applications rely on vector databases and embeddings to power RAG, semantic search, and long-term memory features. Embeddings convert text, images, or other data into numerical representations that capture meaning and context, while vector databases store and retrieve those embeddings based on similarity rather than exact keyword matches.
Instead of searching for the exact phrase “password reset policy,” a vector database can identify documents that are semantically related to the query, even if they use different wording. This is what allows many AI assistants to retrieve relevant internal documents and generate context-aware responses.
However, these systems also introduce new security risks if they’re not properly protected. Vector and embedding weaknesses occur when attackers manipulate, poison, extract, or abuse embedding data to influence model behavior or gain access to sensitive information.
In the paper Text Embeddings Reveal (Almost) as Much as Text, researchers created a model that recovered 92% of 32-token text inputs exactly. The researchers then recovered 89% of full names from embedded clinical notes, highlighting the risk to privacy if vector databases and embeddings aren’t properly secured.
(LLM09:2025) Misinformation
LLMs are designed to generate plausible responses, not verify facts. As a result, they can confidently produce inaccurate or entirely fabricated information, commonly referred to as hallucinations. OWASP classifies this as a security risk because organizations may act on incorrect AI-generated content without realizing it’s wrong.
(LLM10:2025) Unbounded consumption
LLM applications can consume significant amounts of compute power, memory, storage, and API resources. Without proper limits in place, attackers, or even legitimate users, can drive excessive usage that increases costs or causes service issues.
OWASP refers to this as unbounded consumption: situations where AI systems fail to properly restrict resource usage, allowing models or connected services to be abused at scale. One example is attackers sending resource-intensive queries designed to maximize token usage and inference costs. In applications connected to external tools or APIs, poorly controlled AI agents may also trigger excessive automated actions, creating downstream service disruption or spiraling cloud costs.
What the OWASP Top 10 means for LLM security
The OWASP Top 10 for LLM Applications highlights that, while AI systems introduce new attack surfaces, they do not have to be inherently insecure. Many of the risks on the list are extensions of problems security teams already understand. The difference is that LLMs combine natural language interfaces, dynamic behavior, and access to external systems in ways that can make those risks harder to predict. As organizations deploy these systems more widely, security controls need to evolve alongside them.
The good news is that OWASP’s guidance is practical and actionable. Most of the recommended mitigations follow familiar security principles: least privilege access, strong identity controls, input validation, secure supply chain management, monitoring, and human oversight for high-impact actions. In other words, secure AI systems are usually built the same way secure software systems are built.
How Outpost24 helps
Organizations need to ensure that AI and LLM systems are deployed securely, and testing plays a key role in delivering that assurance. Outpost24’s AI penetration testing services helps organizations confidently secure their AI investments through:
- CREST-certified testing delivered by experienced specialists, using AI-specific methodologies and OSAI+ guidelines.
- Comprehensive adversarial testing that covers that full AI attack surface, including prompts, RAG pipelines, agents and connected systems.
- Audit-ready reporting and remediation guidance, with findings mapped to the OWASP Top 10 for LLM Applications.
If you’re looking to understand how resilient your AI systems really are, contact us today or book a demo.
About the Author
